Architecture
Aggregator service consists of three main parts:
- Consumer that reads (consumes) Insights OCP messages from specified message broker. Usually Kafka broker is used but it might be possible to develop a interface for different broker. Insights OCP messages are basically encoded in JSON and contain results generated by rule engine. Different consumer can be selected to consume and process DVO Recommendations.
- HTTP or HTTPS server that exposes REST API endpoints that can be used to read list of organizations, list of clusters, read rules results for selected cluster etc. Additionally, basic metrics are exposed as well. Those metrics is configured to be consumed by Prometheus and visualized by Grafana.
- Storage backend which is some instance of SQL database or Redis storage. Currently only PostgreSQL is fully supported, but more SQL databases might be added later.
Whole data flow
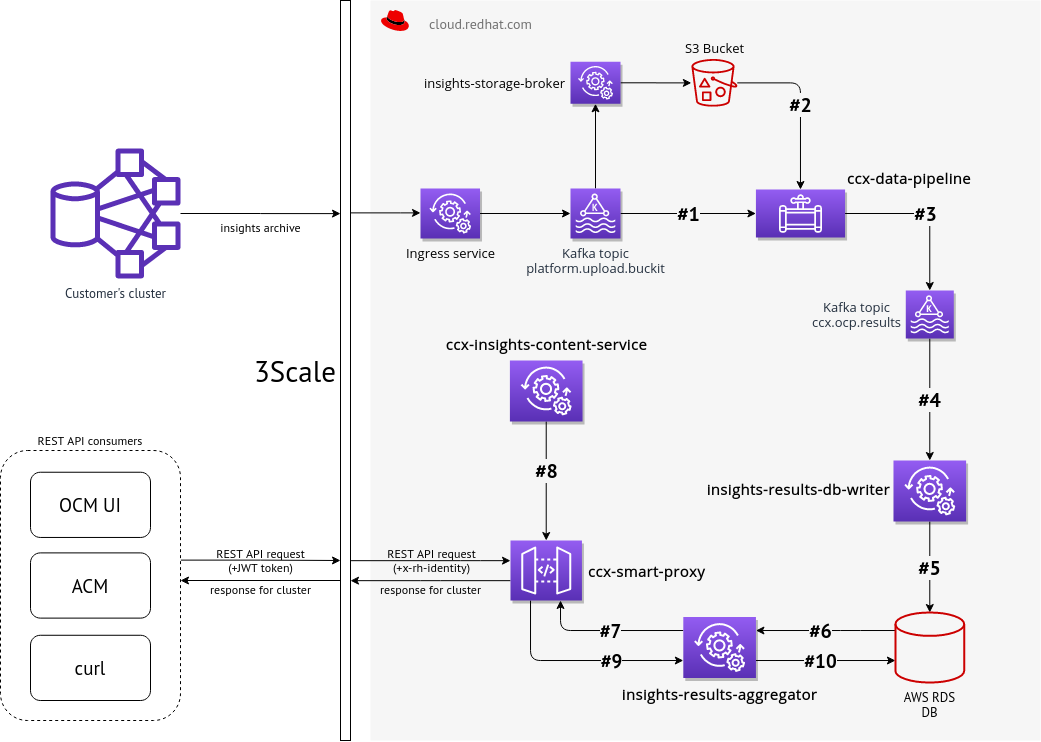
- Event about new data from insights operator is consumed from Kafka. That event contains (among other things) URL to S3 Bucket
- Insights operator data is read from S3 Bucket and Insights OCP rules are applied to that data. Alternatively DVO rules are applied to the same data.
- Results (basically organization ID + cluster name + insights OCP recommendations JSON or DVO recommendations) are stored back into Kafka, but into different topic
- That results are consumed by Insights rules aggregator service that caches them (i.e. stores them into selected database).
- The service provides such data via REST API to other tools, like OpenShift Cluster Manager web UI, OpenShift console, etc.
Optionally, a so called organization allowlist can be enabled by the configuration variable
enable_org_allowlist, which enables processing of a .csv file containing organization IDs (path
specified by the config variable org_allowlist) and allows report processing only for these
organizations. This feature is disabled by default, and might be removed altogether in the near
future.
NOTE
Detailed information about the exact format of consumed data from Kafka topic is available at
https://redhatinsights.github.io/insights-data-schemas/ccx_ocp_results_topic.html