Data flow
The “end-to-end” data flow is described there (including Notification Writer service part):
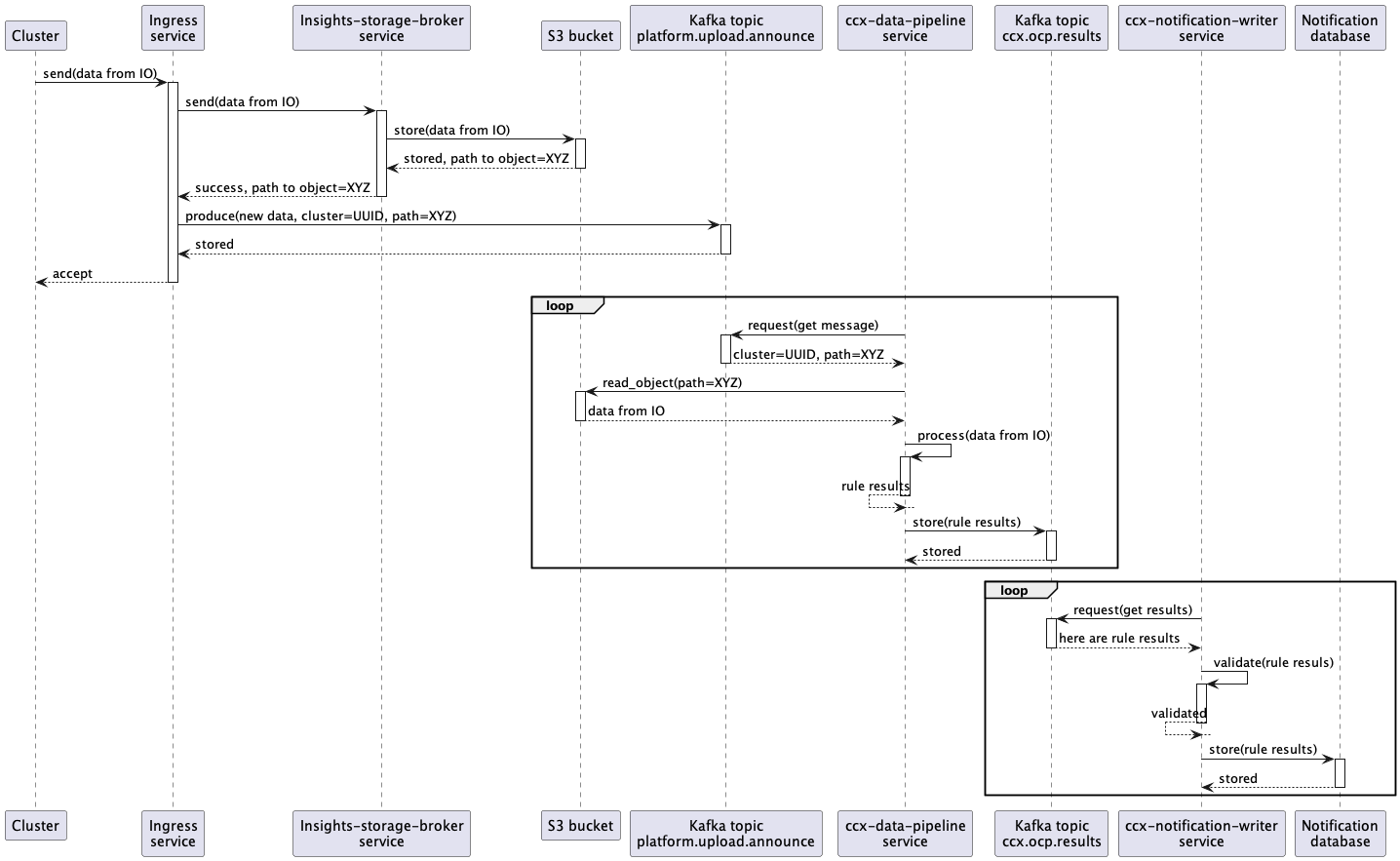
- A customer cluster with Insights Operator installed sends new data containing info about the cluster into Ingress service
- The Ingress service consumes the data, writes them into an S3 Bucket, and produces a new message into a Kafka topic named
platform.upload.announce. - The CCX Data pipeline service consumes the message from the
platform.upload.announceKafka topic. - That message represents an event that contains (among other things) an URL to S3 Bucket.
- Insights operator data is read from S3 Bucket and insights rules are applied to that data in
ccx-data-pipelineservice. - Results (basically
organization ID+cluster name+insights results JSON) are stored back into Kafka, but into different topic namedccx.ocp.results. - That results are consumed by
ccx-notification-writerservice. ccx-notification-writerservice stores insights results into AWS RDS database intonew_reportstable.- Content of that table is consumed by
ccx-notification-serviceperiodically. - Newest results from
new_reportstable is compared with results stored inreportedtable. The records used for the comparison depend on the configured cooldown time. - If changes (new issues) has been found, notification message is sent into Kafka topic named
platform.notifications.ingress. The expected format of the message can be found here. - New issues is also sent to Service Log via REST API. To use the Service Log API, the
ccx-notification-serviceuses the credentials stored in vault. - The newest result is stored into
reportedtable to be used in the nextccx-notification-serviceiteration.
Remarks
- Steps 1 to 5 are shared with the CCX Data pipeline
- Steps 7 and 8 are performed by
ccx-notification-writerservice. - Steps 9 to 12 are performed by
ccx-notification-serviceservice.
Sequence diagram