Insights Data Schemas
Internal data pipeline
Internal data pipeline is responsible for processing Insights Operator archives, transforming data, and aggregating results into reports that later will be served by API and UI.
It takes care of OpenShift Lightspeed generated archives, storing them into an internal storage.
Whole data flow
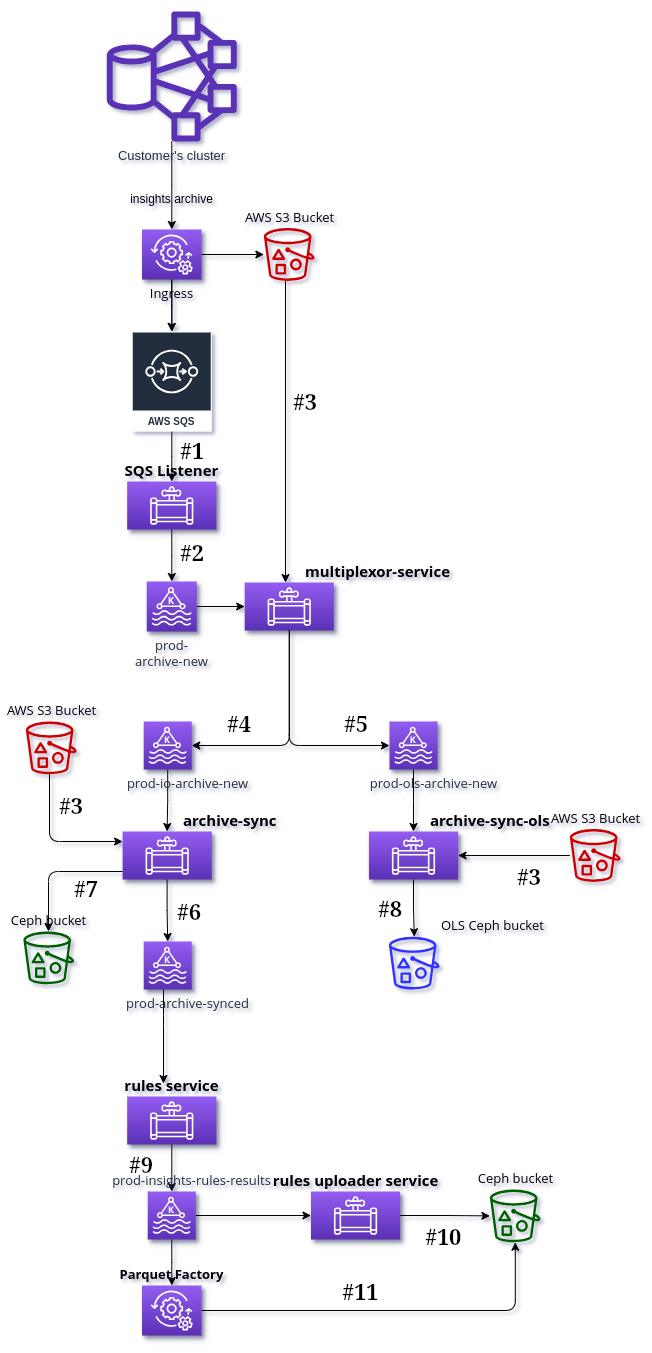
SQS listener service listens to notifications sent to AWS SQS (Simple Queue
Service) about new files in the S3 bucket. It sends a message with S3 path of
the file to [qa|prod]-archive-new Kafka topic for every new file in S3.
Multiplexor Service downloads every archive specified by the path from
[qa|prod]-archive-new Kafka topic, and checks if it is an Insights Operator
archive or an Openshift Lightspeed one. Those archives will be published
respectively into [qa|prod]-io-archive-new and [qa|prod]-ols-archive-new
Kafka topics.
Archive Sync Service synchronizes every new archive by reading the related
information from [qa|prod]-io-archive-new Kafka topic, downloading the archive
from AWS S3 and uploading it to Internal Ceph bucket. Information about
synchronized archive and its metadata are sent to [qa|prod]-archive-synced
Kafka topic.
Archive Sync OLS Service synchorizes every new archive by reading the related
information from [qa|prod]-ols-archive-new Kafka topic, downloading the archive
from AWS S3 and uploading it to Internal Ceph bucket. The bucket where the
Openshift Lightspeed archives are stored is different from the Insights Operator
ones.
Rules Service runs rules for all archives synced in Internal Ceph bucket. It
reads messages from [qa|prod]-archive-synced Kafka topic to know about incoming
archives in Ceph and it will download the archive from Internal Ceph bucket. The
result of the applied rules is sent to [qa|prod]-insights-rules-results Kafka
topic.
Rules Uploader Service writes the results published in the
[qa|prod]-insights-rules-results into a JSON file and uploads it to DataHub
(Ceph) bucket.
Parquet Factory is a program that can read data from [qa|prod]-insights-rules-results
Kafka topic, aggregate the data received from it and generate a set of Parquet files
with the aggregated data, storing them in a selected S3 or Ceph bucket. It is used
to generate different data aggregations in the CCX Internal Data Pipeline,
reading data from Kafka topics.
Architecture diagram
Data format descriptions
- Incoming messages from SQS
- Messages produced by SQS listener
- Raw data stored in S3 bucket
- Messages produced by multiplexor-service in
io-archive-newtopic - Messages produced by multiplexor-service in
ols-archive-newtopic - Raw data stored into Ceph bucket
- Raw data stored into Ceph bucket (OLS)
- Messages produced by archive-sync-service
- Messages produced by Rules service
- Messages produced by Features service
- Rules results stored into Ceph bucket by rules-uploader-service
- Generated parquet files
Parquet factory
Parquet Factory is a program that can read data from several data sources, aggregate the data received from them and generate a set of Parquet files with the aggregated data, storing them in a S3 bucket. It is used to generate different data aggregations in the CCX Internal Data Pipeline, currently it only reads data from one Kafka topics.