Insights Data Schemas
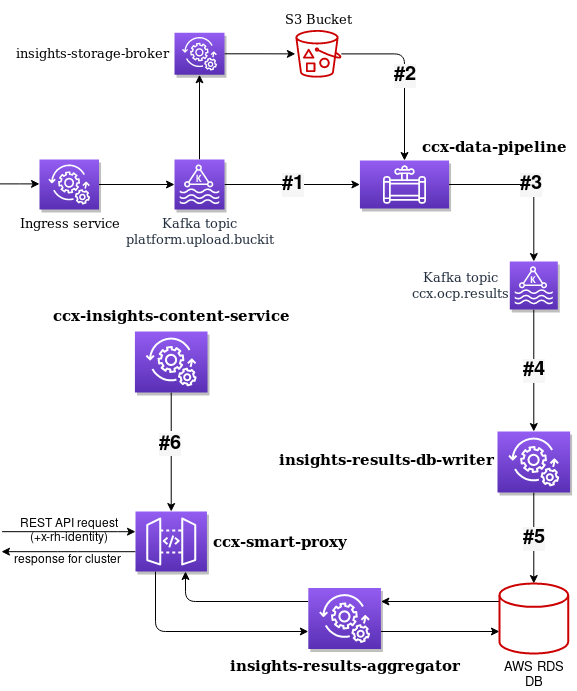
External data pipeline
Whole data flow
- Event about new data from insights operator is consumed from Kafka. That event contains (among other things) URL to S3 Bucket
- Insights operator data is read from S3 Bucket and Insights rules are applied to that data
- Results (basically organization ID + account number + cluster name + insights results JSON) are stored back into Kafka, but into different topic
- That results are consumed by Insights rules aggregator service that caches them
- The service provides such data via REST API to other tools, like OpenShift Cluster Manager web UI, OpenShift console, etc.
Architecture diagram